到Solr的官方安全通告页面看看近三年主要有这么几个漏洞:
CVE-2019-0193
dataConfig参数可包含脚本,而且可通过HTTP请求指定,然后通过脚本转换器转换后执行任意js->java代码。
已分析:
https://mp.weixin.qq.com/s/typLOXZCev_9WH_Ux0s6oA
注意需要将dataimporthandler驱动放到WEB-INF/lib目录下
若出现以下错误:原因是未能找到dataimporthandler类名,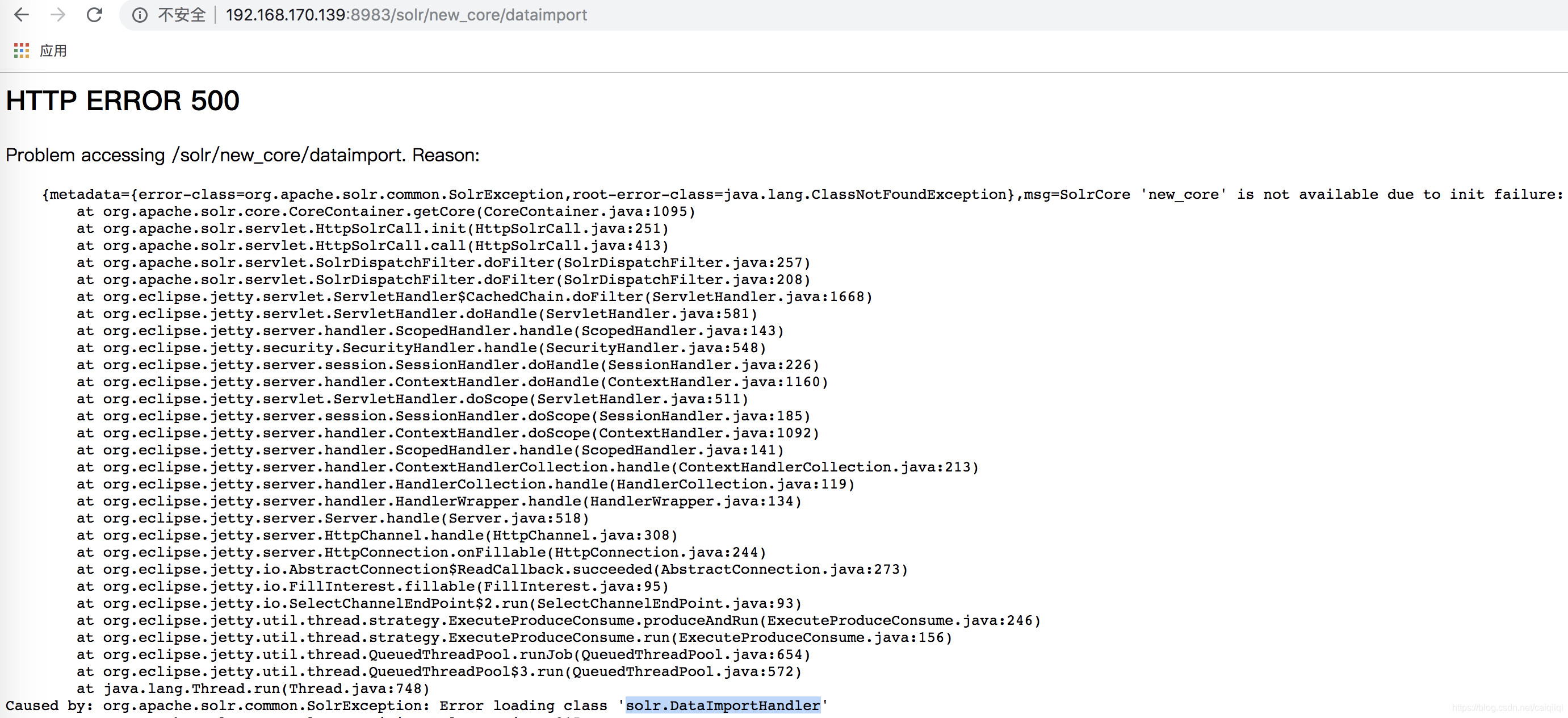
需要将jar包复制到WEB-INF/lib目录下。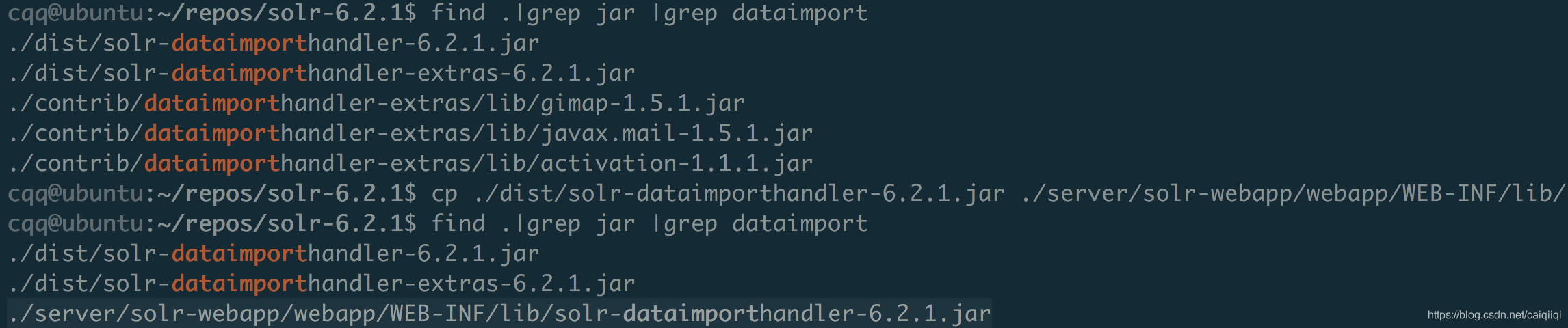
CVE-2019-0192
反序列化漏洞,待分析:
https://blog.csdn.net/caiqiiqi/article/details/88431504
CVE-2018-8026
(这个没有在Solr的官方安全公告里出现,奇怪)
漏洞公告及详细描述:
https://mail-archives.apache.org/mod_mbox/lucene-solr-user/201807.mbox/%3C0cdc01d413b7%24f97ba580%24ec72f080%24%40apache.org%3E
复现参考:
https://xz.aliyun.com/t/2448
需要SolrCloud部署方式(Solr4.0版本以后基于Solr和Zookeeper的分布式搜索方案)
参考Solr中文文档:https://www.w3cschool.cn/solr_doc/solr_doc-5sqm2jw0.html
CVE-2018-8010
CVE-2018-1308
之前有一个XXE漏洞: CVE-2018-1308
也是出在DataImportHandler可以 接收用户提供的xml作为配置文件。与CVE-2019-0193不同的是,这里只是引入外部实体,导致读取文件。
这里的缓解措施也只能是在配置文件solrconfig.xml中禁用掉data import handler功能。
原文:https://seclists.org/oss-sec/2018/q2/22
不过这个的修复方式是在org/apache/solr/handler/dataimport/DataImporter.java
参考:https://issues.apache.org/jira/secure/attachment/12910207/SOLR-11971.patch
https://github.com/apache/lucene-solr/commit/02c693f3713add1b4891cbaa87127de3a55c10f7
麦香的漏洞分析报告?:
https://issues.apache.org/jira/secure/attachment/12910190/ApacheSolrDIH-XXE.pdf
读取部分文件的漏洞演示(不能读取内容开头为#的文件):
https://github.com/shadowsock5/notes/blob/master/payloads.md
CVE-2017-12629
这个CVE包含两个漏洞,一个XXE,一个RCE。
想要RCE,需要以下步骤:
1、先通过XXE创建一个新的collection(如果已经知道可用的collection的名字了就不需要这一步了);
2、本地nc监听:nc -lv 4444
3、通过XXE添加一个RunExecutableListener
|
4、update这个newcollection:
|
5、然后就能在nc上收到反弹回来的shell了。
邮件列表:
http://mail-archives.us.apache.org/mod_mbox/www-announce/201710.mbox/%3CCAOOKt51UO_6Vy%3Dj8W%3Dx1pMbLW9VJfZyFWz7pAnXJC_OAdSZubA%40mail.gmail.com%3E
漏洞详细描述(带详细PoC):
http://mail-archives.apache.org/mod_mbox/lucene-dev/201710.mbox/%3CCAJEmKoC%2BeQdP-E6BKBVDaR_43fRs1A-hOLO3JYuemmUcr1R%2BTA%40mail.gmail.com%3E
CVE-2017-3164
shards参数的SSRF,可指定任意url,然后返回响应。
参考:
https://issues.apache.org/jira/browse/SOLR-12770
CVE-2017-3163
https://issues.apache.org/jira/browse/SOLR-10031
CVE-2018-1308
官方公告:
https://issues.apache.org/jira/browse/SOLR-11971
参考:
https://issues.apache.org/jira/secure/attachment/12910190/ApacheSolrDIH-XXE.pdf
若使用未经url编码的payload:
|
则出现这样的错误:
经过url编码之后的payload:
|
实现了SSRF。
想要实现任意文件读取,还需要一些额外的步骤。
需要用到com.sun.org.apache.xerces.internal.parsers: